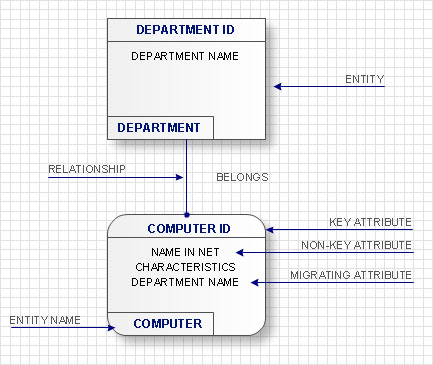
The first entity in the above mentioned examples is connected with several entities of the second type therefore such tie is called ‘one to many’. At that, the first entity is called parental, and subsequent are daughters. (Child?) On the diagram ties are represented in the form of lines with the dot at the end and with the name specification. Also there are ties of the type ‘many to many’. They are used at the starting stage of the projection and represented in the form of lines with dots at both ends. As an example of such tie is the tie between the mass of PASSNGERS which by a number of BUSES. In future such ties must be necessarily elaborated in details.
Accordingly to IDEF1x standard entities are represented in the form of rectangles with definite fields. At the upper part of the rectangle the key information of the entity, also called the primary key, is located. This information is selected for unique entity identification, e.g. ID of a computer.
At the lower part an area with non key attributes is located, e.g. the name of the computer in the network, the current worker, who works with the computer, works fulfilled on the given computer and computer characteristics.
At the left bottom part an area with the entity name on the diagram is located, e.g. COMPUTER, WORKER or DEPARTMENT.
In the capacity of key attributes several attributes or even attribute groups can be chosen. Attributes, which can be key attributes, are called candidates of key attributes. Key attributes selection rules consist in the following:
- Key attributes must uniquely identify an entity;
- Key attributes mustn’t contain empty or NULL values;
- Key attributes can’t change with time. At key attributes change the entity changes also;
- Key attributes must be brief as far as possible for convenience of the further processing or indexation. For instance these can be alphanumeric symbols of the entity ID.
At choice of the primary key it is often used the so-called surrogate key, which represents an arbitrary number, existing only within the limits of the concrete data base and is unique for each
If entities on the IDEF1x diagram are connected one to each other, then the parent entity transfers key attributes to a child entity. Such attributes are called migratory or external keys. For example, COMPUTER which is on DEPARTMENT balance will have as an external key one of its key attributes the DEPARTMENT ID. Such child entities are called dependent as their identification depends on the key attributes of the parent entity. Dependent entities are divided into those entities which cannot exist without parent entity and those that can’t be identified without parent entity. For example, the INFORMATION on the COMPUTER cannot exist without it or without an external carrier, which are parent entities for it. In its turn, COMPUTER can exist without a DEPARTMENT, but accordingly to the accepted notations, cannot be identified not being the part of any department. Independent entities are those which are not dependent in identification on other entities. These are entities into which the system is divided in the first place and further structuring will happen within the limits of these entities. For example as a rule an organization is divided into DEPARTMENTS which are independent entities as they have its unique identifier not dependent on other entities. All other entities in their identification will depend on ID of the department they belong to.
Accordingly to IDEF1x standard, dependent entities are represented in the form of rounded rectangles, and non-dependent – in the form of usual rectangles.
The ties between entities can be identifying (transferring the external key to a child entity) and non-identifying (transferring data to the area of child entity data). Identifying ties are represented with a solid line, and non-identifying- with dotted line. As an example of identifying tie can be the tie between the DEPARTMENT and any of the resources, which is allotted between DEPARTMENTS and belong not to any of the DEPARTMENTS but to the organization as a whole.
The main advantage of the IDEF1X is the rigid and strict standardization of modeling. Such standardization allows to avoid misunderstandings during the analysis of the constructed model which is the significant advantage against other modeling methods without data bases.
TEN RELATED HOW TO's:
If you want to find a way to understand complex things in minutes, you should try to visualize data. One of the most useful tool for this is creating a flowchart, which is a diagram representing stages of some process in sequential order. There are so many possible uses of flowcharts and you can find tons of flow charts examples and predesigned templates on the Internet. Warehouse flowchart is often used for describing workflow and business process mapping. Using your imagination, you can simplify your job or daily routine with flowcharts.
Warehouse flowcharts are used to document product and information flow between sources of supply and consumers. The flowchart provides the staged guidance on how to manage each aspect of warehousing and describes such aspects as receiving of supplies; control of quality; shipment and storage and corresponding document flow. Warehouse flowchart, being actual is a good source of information. It indicates the stepwise way to complete the warehouse and inventory management process flow. Also it can be very useful for an inventory and audit procedures.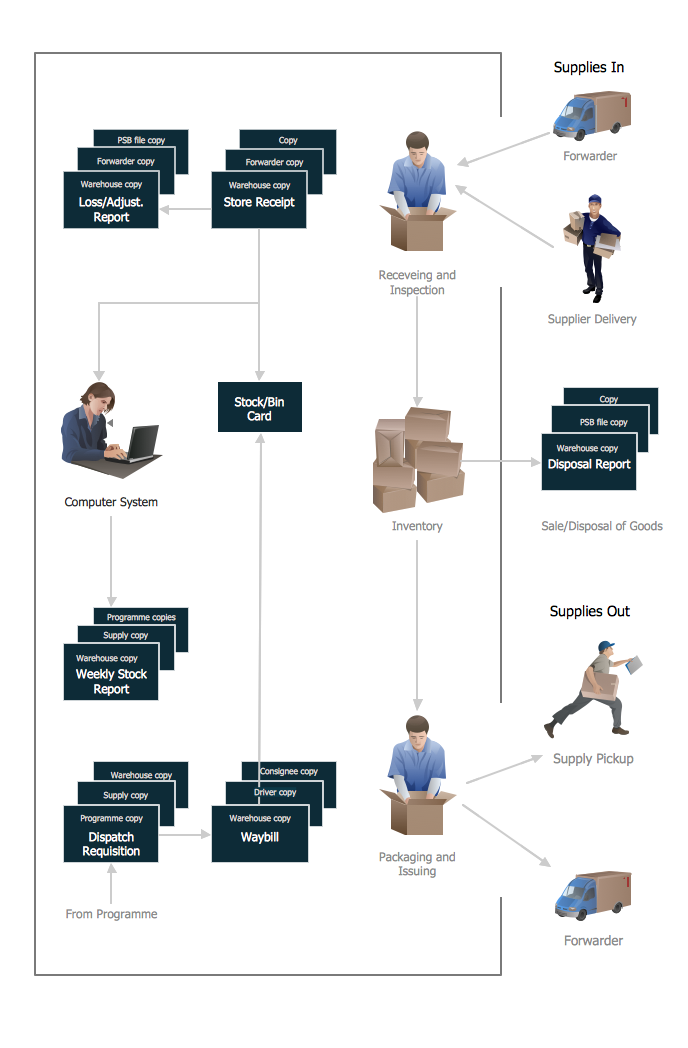
Picture: Flow Chart Example: Warehouse Flowchart
Related Solution:
If you are just a beginner in drawing flowcharts, it may seem that a sheet of paper and a pen are just enough. However, at the time you would want to share your results, diagramming applications would suite you better. it’s very easy to create diagrams that way and to discover new kinds of flowcharts.
The huge collection of sample ConceptDraw diagrams, charts, illustrations and other types of business drawings includes a wide range of business themes. A huge number of graphic images of ConceptDraw documents is divides on business application areas according to business-oriented solutions for which they were made.Here is a short visual list of samples of flowcharts, process diagrams, UML models, management charts, computer network diagrams, maps, infographics, illustrations, etc. In short, each ConceptDraw solution is accompanied with at least ten samples representing some particular examples of the application of the given chart.
Picture: Applications
When trying to figure out the nature of the problems occurring within a project, there are many ways to develop such understanding. One of the most common ways to document processes for further improvement is to draw a process flowchart, which depicts the activities of the process arranged in sequential order — this is business process management. ConceptDraw DIAGRAM is business process mapping software with impressive range of productivity features for business process management and classic project management. This business process management software is helpful for many purposes from different payment processes, or manufacturing processes to chemical processes. Business process mapping flowcharts helps clarify the actual workflow of different people engaged in the same process. This samples were made with ConceptDraw DIAGRAM — business process mapping software for flowcharting and used as classic visio alternative because its briefly named "visio for mac" and for windows, this sort of software named the business process management tools.
This flowchart diagram shows a process flow of project management. The diagram that is presented here depicts the project life cycle that is basic for the most of project management methods. Breaking a project into phases allows to track it in the proper manner. Through separation on phases, the total workflow of a project is divided into some foreseeable components, thus making it easier to follow the project status. A project life cycle commonly includes: initiation, definition, design, development and implementation phases. Distinguished method to show parallel and interdependent processes, as well as project life cycle relationships. A flowchart diagram is often used as visual guide to project. For instance, it used by marketing project management software for visualizing stages of marketing activities or as project management workflow tools. Created with ConceptDraw DIAGRAM — business process mapping software which is flowcharting visio alternative or shortly its visio for mac, this sort of software platform often named the business process management tools.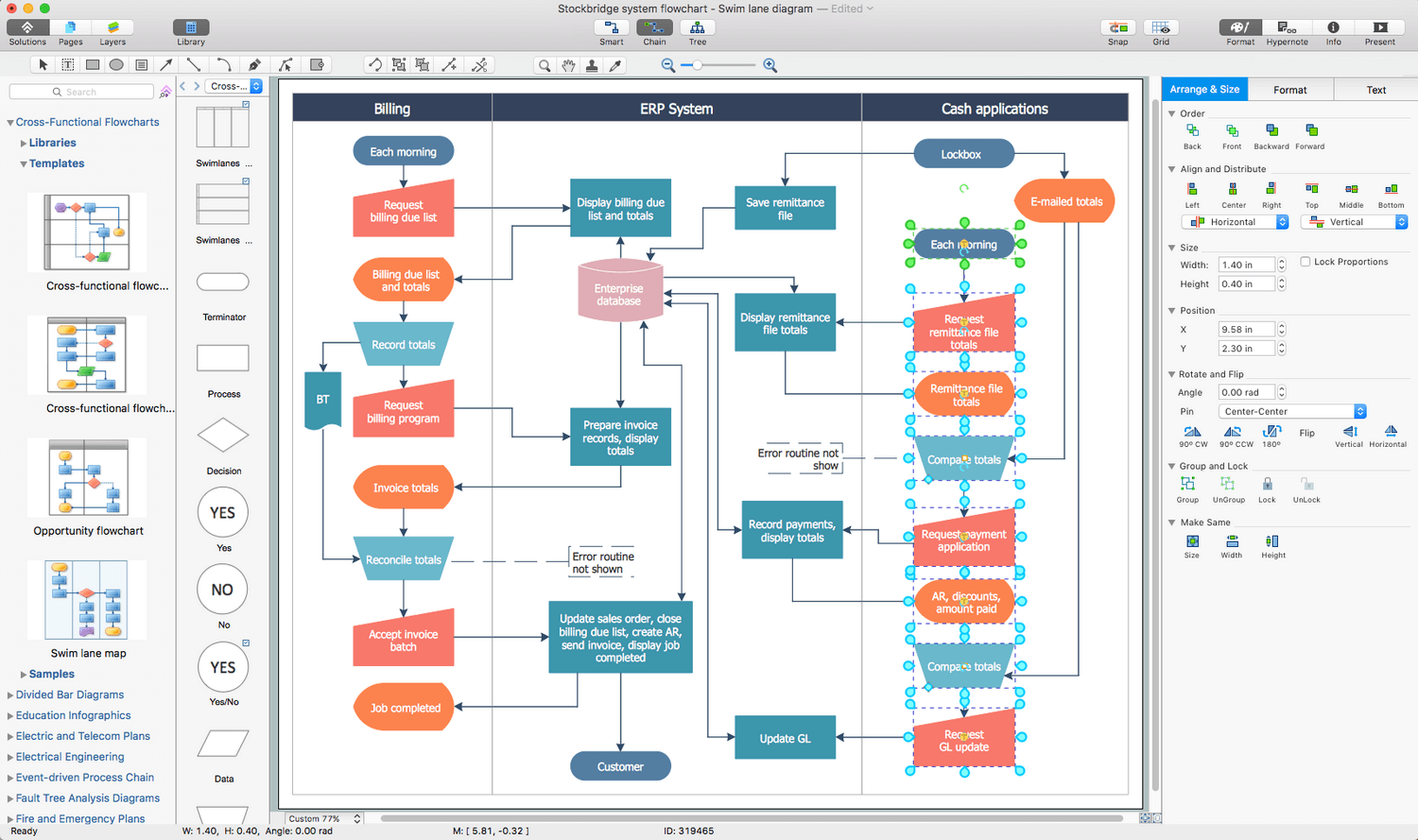
Picture: Process Flowchart: A Step-by-Step Comprehensive Guide
Related Solution:
Creating of Entity-Relationship Diagrams (ERDs) is a complex process that requires convenient, automated tools. ConceptDraw DIAGRAM diagramming and vector drawing software offers a powerful ER Diagram Tool - the Entity-Relationship Diagram (ERD) Solution from the Software Development Area.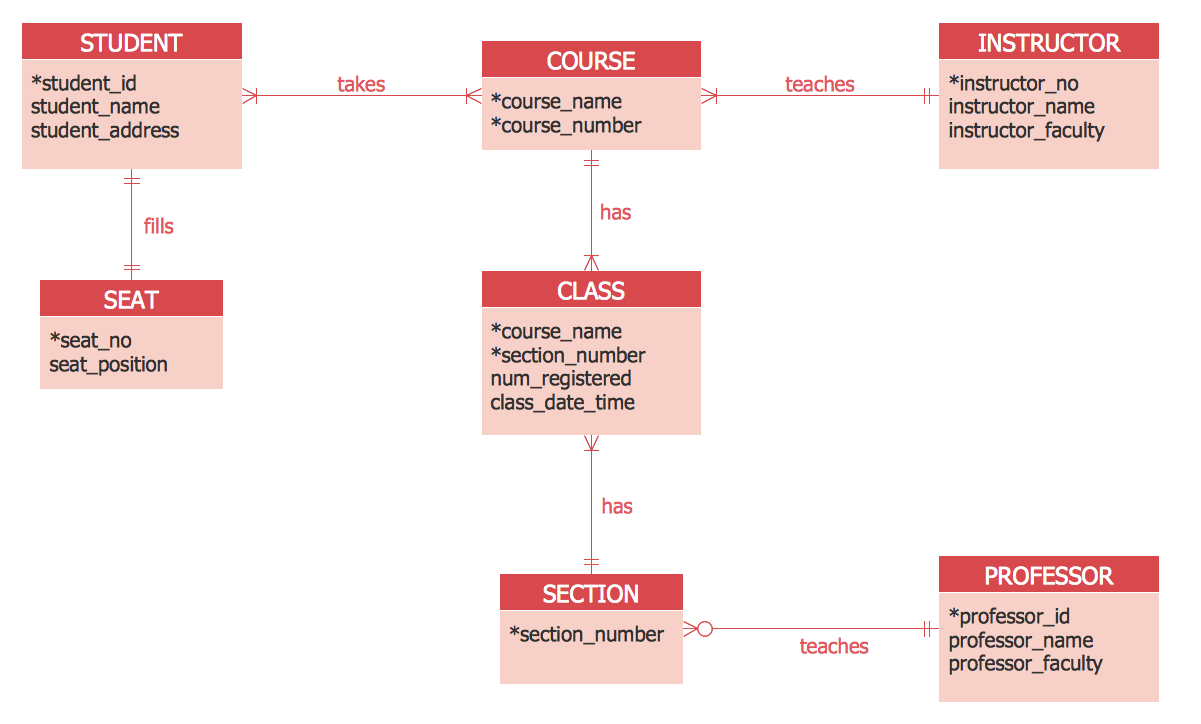
Picture: ER Diagram Tool
Related Solution:
While creating flowcharts and process flow diagrams, you should use special objects to define different statements, so anyone aware of flowcharts can get your scheme right. There is a short and an extended list of basic flowchart symbols and their meaning. Basic flowchart symbols include terminator objects, rectangles for describing steps of a process, diamonds representing appearing conditions and questions and parallelograms to show incoming data.
This diagram gives a general review of the standard symbols that are used when creating flowcharts and process flow diagrams. The practice of using a set of standard flowchart symbols was admitted in order to make flowcharts and other process flow diagrams created by any person properly understandable by other people. The flowchart symbols depict different kinds of actions and phases in a process. The sequence of the actions, and the relationships between them are shown by special lines and arrows. There are a large number of flowchart symbols. Which of them can be used in the particular diagram depends on its type. For instance, some symbols used in data flow diagrams usually are not used in the process flowcharts. Business process system use exactly these flowchart symbols.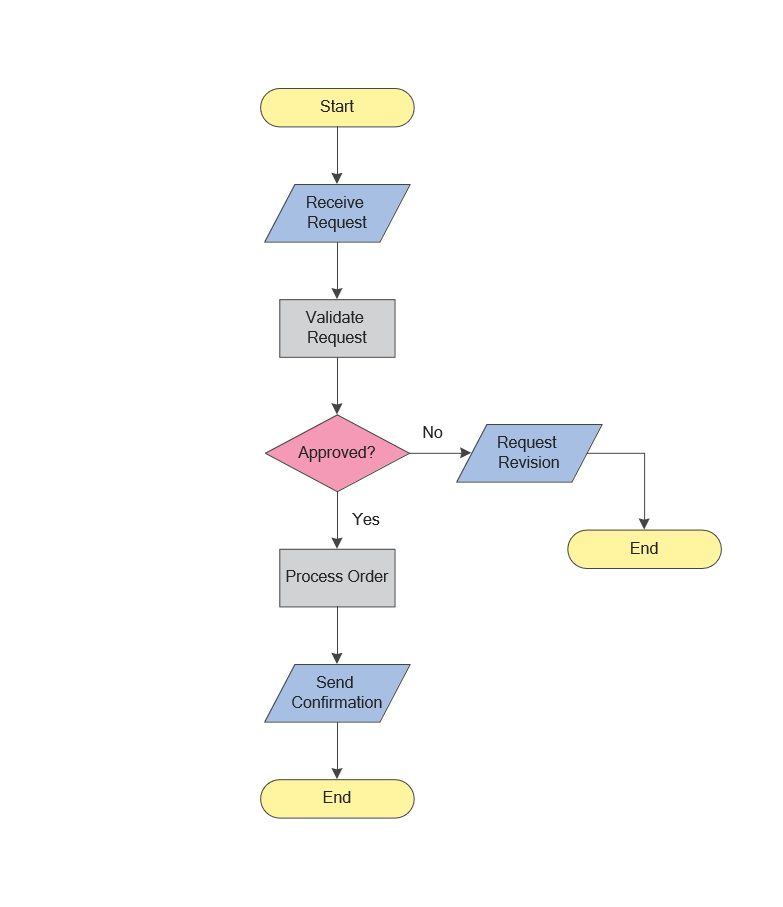
Picture: Flowchart Symbols: Meaning and Examples
Related Solution:
ConceptDraw DIAGRAM diagramming and vector drawing software offers the Fault Tree Analysis Diagrams Solution from the Industrial Engineering Area of ConceptDraw Solution Park for quick and easy creating the Fault Tree Diagram of any degree of detailing.
Picture: Fault Tree Diagram
Related Solution:
When talking about engineering, one should define all the terms used, so anybody could understand the topic. Typical network glossary contains definitions of numerous network appliances, types of networks and cable systems. The understanding of basic is crucial for server management, network administration and investigating problems.
The network glossary defines terms related to networking and communications. The most of glossary items has their visual representation in ConceptDraw DIAGRAM libraries of the Computer Network Diagrams solution. This illustration presents a local area network (LAN) diagram. It designed to show the way the interaction of network devices in a local network. The diagram uses a library containing symbols of network equipment, connections and the end-point devices such as network printer, hubs, server, modem and finally computers (PC, mac, laptop). This diagram depicts a physical LAN topology.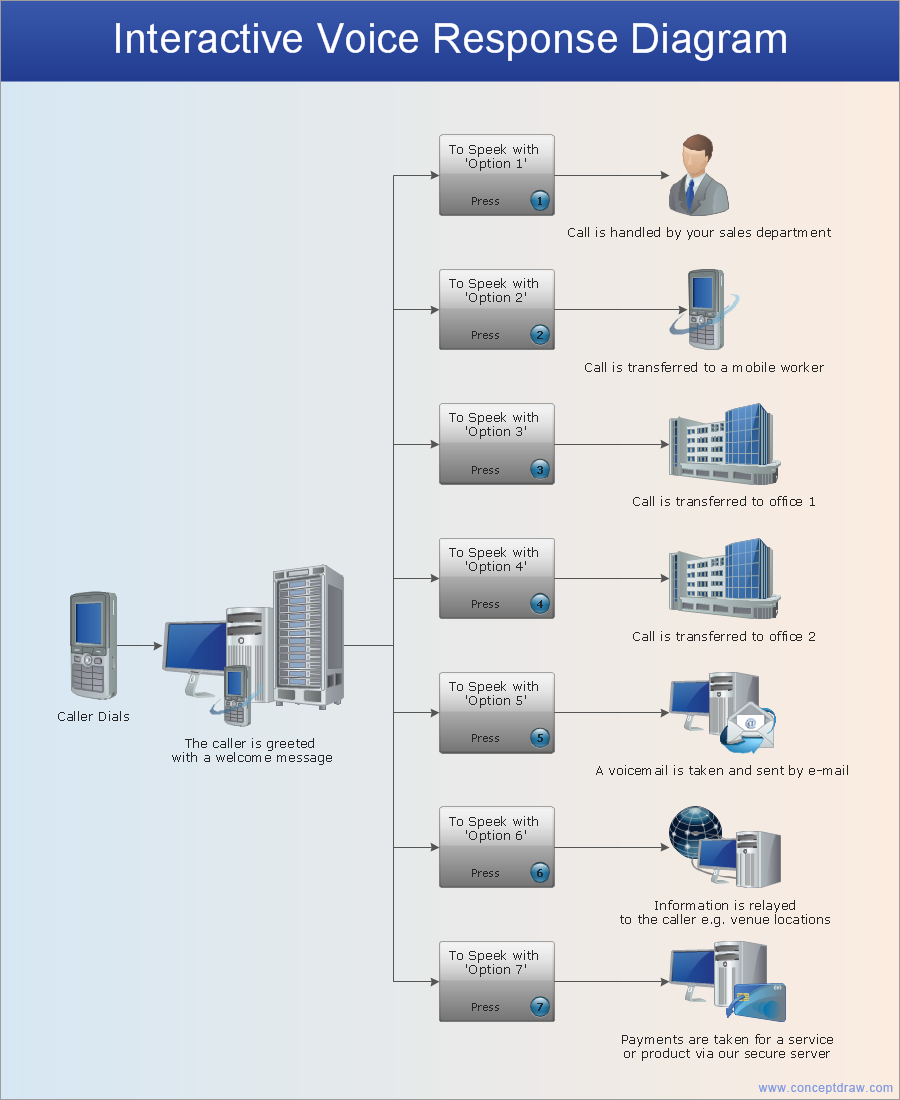
Picture: Network Glossary Definition
Related Solution:
Action Plan - For the action planning define people and groups involvement in corrective actions by roles, identify logical sequences of scheduled actions and critical path of problem solving, identify possible risks of action plan and propose preventive actions.
ConceptDraw Office suite is a software for decision making and action plan.
Picture: The Action Plan
A waterfall model describes software development process as a sequence of phases that flow downwards. SSADM is one of the implementations of waterfall method. It’s easier to learn about structured systems analysis and design method (SSADM) with ConceptDraw DIAGRAM because this software has appropriate tools for creating data flow diagrams. You can use all the three main techniques of SSADM method with special tools and predesigned templates.
This data flow diagram illustrates the Structured Systems Analysis and Design Method. This method method considers analysis, projecting and documenting of information systems. Data flow models are the most important elements of SSADM and data flow diagrams are usually used for their description. It includes the analysis and description of a system as well as visualization of possible issues.
Picture: Structured Systems Analysis and Design Method. SSADM with ConceptDraw DIAGRAM
Related Solution:
The excellent possibility to create attractive Cross Functional Flowcharts for step-by-step visualization the operations of a business process flow of any degree of detailing is offered by ConceptDraw’s Cross-Functional Flowcharts solution. The extensive selection of commonly used vector cross functional flowchart symbols allow you to demonstrate the document flow in organization, to represent each team member’s responsibilities and how processes get shared or transferred between different teams and departments.
Picture: Cross Functional Flowchart Symbols
Related Solution: